倒排索引是搜索引擎中最重要的数据组织方式,实现的目的是通过某个词,定位到包含该词的所有文章,当然文章可以有很多。这和一般的建索引思路不太一致,一般是通过某文章找到该文章中的某个词,所以这种倒着查找的方式名为倒排索引。
可能大多数人想到索引、查找等问题时,首先想到的是使用数据库。数据库确实是一个存储和查找的好方式,尤其在数据关系复杂的情况下,但对于搜索引擎来说,数据量实在是太大,而且搜索引擎数据查找模式固定、查找方式简单。所以在追求查找效率和并发性的前提下,目前的主流搜素引擎都是使用倒排索引。
前文提到了,倒排索引达到的目的简单来说其实就是用户一次搜索的过程,即用户在搜索框输入一条query,后台需要查找包含该query的所有网页(其中query视为词,网页视为文章)。下图是倒排索引的数据组织结构图:
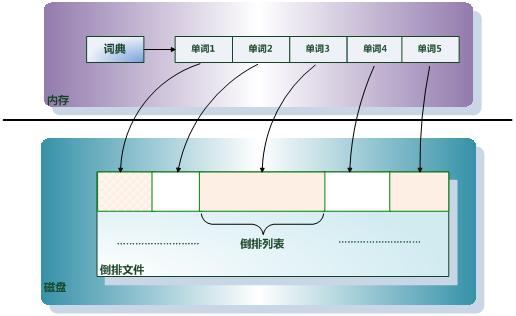
从图中可以看出,倒排索引一般分为三个模块(有些因为倒排列表k、v对中v的值太大,也会建立四个模块,比如我厂的索引☺)。这三个模块分别为:词典列表、倒排列表、倒排数据。图中描述的是把词典列表放入内存,其他放入硬盘,但目前我接触到的倒排索引是将这三个模块都读入内存,在服务器资源充足的情况下,这样也能提升索引速度。
1、词典列表
简单来说就是以词为key,该词在倒排列表的位置index以及文章数量len为v,建立map结构。v定位的是包含该词的所有文章在倒排列表的起始位置index,以及文章数量len,即只要遍历倒排列表中以index起始,长度为len的数据,就可以得到所有需要的文章。其中key可以用词的MD5,减少空间。
2、倒排列表
倒排列表可以为一个数组结构,k即文章的index(对于每一个文章是自加的),v为文章在倒排数据中的实际寻址地址(可以理解为虚地址的实际地址)。这样,对应一个词,即可以寻址到其实际存储地址。
3、倒排数据
倒排数据即是最后需要查找的文章的内容了,通过倒排列表的实际地址得到,其可以是一个char结构,在制作倒排数据的时候,手动对每一个文章末尾添加’\0’。
以上就是一个简单的倒排索引的数据以及寻址方式了,当然在复杂的搜索环境中,倒排数据中会增加一些统计方面的工作(比如词在文章的第几个位置,TF·IDF信息等,也有通过生成另外一份数据来存储文章的相关信息,k为文章,v为需要的信息),下面说一下生成倒排索引的算法逻辑。
分词、停用词、英文去词根之类的就不谈了,这里假设已经有了对文章分好词的数据N,即每一行有两列,第一列为词W的集合,第二列为包含该词的文章T的集合,有:
生成算法
- for w in W:
- for t in T:
- if 文章t不在倒排数据中:
- 将文章t写入倒排数据.以’\0’结束,并生成倒排列表的index(从0自加)和v(即刚刚写入倒排数据的地址)
- else:
- 返回倒排数据的已有地址,生成倒排列表index和v(已有的地址)
- if 文章t不在倒排数据中:
- 每一个词的文章写入倒排完成后,获得该词在倒排列表的第一个文章的indexFirst,以及包含该词的文章集合的数量len,写入词典列表,k为该词,v为indexFirst和len
- for t in T:
参考: 《这就是搜索引擎》